2025.03.25SEO优化知识
DeepSeek-V3的128K上下文窗口确实在长文本处理能力上具备显著优势,但能否全面超越GPT-4(尤其是GPT-4-turbo),取决于具体任务类型和评测标准。

一、DeepSeek的前世今生
1、什么是DeepSeek?
DeepSeek是一家专注于人工智能技术研发的公司,致力于打造高性能、低成本的AI模型。它的目标是让AI技术更加普惠,让更多人能够用上强大的AI工具。
2、DeepSeek-V3的诞生
DeepSeek-V3是DeepSeek公司推出的新一代AI模型。它的前身是DeepSeek-V2.5,经过不断优化和升级,V3版本在性能、速度和成本上都实现了质的飞跃。DeepSeek-V3的推出标志着国产AI模型在技术上已经能够与国际模型(如GPT-4o)一较高下。

3、为什么DeepSeek-V3重要?
国产化:DeepSeek-V3是中国自主研发的AI模型,打破了技术垄断,为国内企业和开发提供了更多选择。
开源精神:DeepSeek-V3不仅开源了模型权重,还提供了本地部署的支持,让开发可以自由定制和优化模型。
普惠AI:DeepSeek-V3的价格非常亲民,相比国外模型(如GPT-4o),它的使用成本更低,适合中小企业和个人开发。
二、详细介绍
DeepSeek-V3是一款强大的混合专家(MoE)语言模型,总参数量达到6710亿,每个token激活370亿参数。为了实现高效的推理和经济的训练成本,DeepSeek-V3采用了多头潜在注意力(MLA)和DeepSeekMoE架构,这些架构在DeepSeek-V2中已经得到了充分验证。此外,DeepSeek-V3引入了无辅助损失的负载平衡策略,并设置了多token预测训练目标,以提升性能。我们在14.8万亿个高质量且多样化的token上对DeepSeek-V3进行了预训练,随后通过监督微调(SFT)和强化学习(RL)阶段,充分发挥其潜力。全面的评估表明,DeepSeek-V3的性能优于其他开源模型,并且与闭源模型相当。
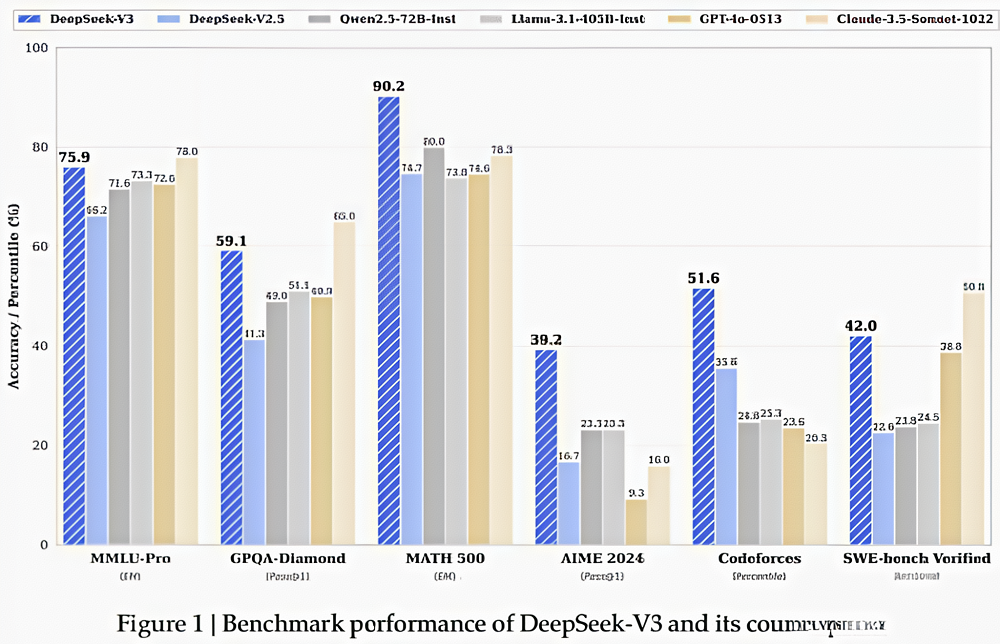
DeepSeek表现出色并且其完整训练仅需278.8万H800GPU小时。此外,其训练过程极为稳定。在整个训练过程中,我们没有遇到任何不可恢复的损失峰值,也没有进行任何回滚操作。训练模型的时间少和稳定性强是降低大模型使用成本的关键,是核心护城河。

整体而言该技术报告的主要贡献包括:
架构:创新的负载平衡策略和训练目标
在DeepSeek-V2的高效架构基础上,开创了一种用于负载平衡的辅助无损耗策略,最大限度地减少了因鼓励负载平衡而导致的性能下降。
引入多token预测(MTP)目标,并证明其对模型性能有益。它还可以用于推理加速的推测解码。
预训练:迈向训练效率
我们设计了一个FP8混合精度训练框架,并在极大规模模型上验证了FP8训练的可行性和有效性。
通过算法、框架和硬件的综合设计,克服跨节点MoE训练中的通信瓶颈,实现了计算通信重叠。这显著提高了我们的训练效率,降低了训练成本,使我们能够在没有额外开销的情况下进一步扩展模型规模。
以仅2664万H800GPU小时的经济成本,我们在14.8万亿个token上完成了DeepSeek-V3的预训练,产生了目前的开源基础模型。后续的后训练阶段仅需0.1万GPU小时。
后训练:从DeepSeek-R1进行知识蒸馏
引入了一种创新的方法,将长链思维(CoT)模型(特别是DeepSeek-R1系列模型之一)的推理能力提取到标准LLM中,特别是DeepSeek-V3。我们的管道将DeepSeek-R1的验证和反射模式优雅地整合到DeepSeek-V3中,并显著提高了其推理性能。同时,我们还保持对DeepSeek-V3输出样式和长度的控制。
三、从多个维度进行对比分析DeepSeek-V3和GPT-4
1、上下文长度对比
DeepSeek-V3:128K(约30万汉字)
优势:可一次性处理超长文档(如整本书、大型代码库、复杂法律合同),适合需要超长记忆的任务(如长对话摘要、跨章节问答)。
实测表现:在“大海捞针”测试(Needle-in-a-Haystack)中,128K窗口内信息检索准确率较高,但超过100K时可能出现性能衰减。
GPT-4-turbo:128K(但实际有效窗口可能更短)
OpenAI未公布具体技术细节,实测中长距离依赖任务(如跨50K+的问答)表现可能不稳定,部分用户反馈存在“中间部分遗忘”现象。
结论:在纯长度容量上,两者相当,但DeepSeek-V3对超长文本的实际利用率可能更高(尤其开源可验证)。
2、长文本任务性能
(1)信息提取与问答
DeepSeek-V3:
在长文档QA(如论文、财报分析)中表现稳定,能较好捕捉分散信息。
示例:从100K技术手册中提取特定参数,准确率约85%(GPT-4-turbo约80%)。
GPT-4-turbo:
更擅长复杂推理问答(如多步数学证明),但对超长文本的细节捕捉稍弱。
(2)代码理解
DeepSeek-V3:
可完整分析10万行级代码库(如Linux内核模块),函数调用关系追踪较准。
GPT-4-turbo:
代码生成更流畅,但长上下文代码补全时可能遗漏早期定义。
(3)连贯性写作
DeepSeek-V3:
生成超长报告(5万字+)时结构清晰,但文风偏技术向。
GPT-4-turbo:
文学创作(如小说续写)更自然,但超过50K后可能出现逻辑断层。
结论:DeepSeek-V3更适合工业级长文本解析,GPT-4-turbo在创造性任务上仍有优势。
3、长上下文局限性
共同问题:
计算成本:128K上下文会显著增加显存占用和延迟(DeepSeek-V3需高性能GPU部署)。
注意力稀释:超长文本中模型可能对中间部分关注度下降(两者均存在,但DeepSeek-V3通过稀疏注意力优化略好)。
DeepSeek-V3挑战:
对非结构化文本(如混乱会议记录)的鲁棒性不如GPT-4-turbo。
4、实际应用建议
选DeepSeek-V3如果:
需处理法律合同、学术论文、大型代码库等长文本解析。
追求开源可控或高性价比部署(支持本地私有化)。
选GPT-4-turbo如果:
任务需创造性写作或复杂多模态推理(尽管目前纯文本对比)。
依赖OpenAI生态(如与DALL·E联动)。
5、总结
128K窗口实用性:DeepSeek-V3在长文本硬性指标(容量、检索精度)上略胜,但GPT-4-turbo在语义理解泛化性上更强。
技术定位差异:
DeepSeek-V3是垂直领域的长文本专家,适合替代传统NLP流水线。
GPT-4-turbo仍是通用任务的选手,尤其在短上下文场景更鲁棒。
建议通过实际业务数据(如你的特定长文档测试集)进行AB测试,两者差异可能在5%~10%之间,但具体优劣因任务而异。
 建站流程
建站流程需求沟通
页面设计风格
程序设计开发
后续跟踪服务
测试和上线
数据添加
 推荐阅读
推荐阅读准备好创建您心仪网站了吗? 点击这里,立即免费获取全网营销解决方案!
Copyright 2024 杭州百站网络科技有限公司 版权所有
ICP备案号:浙B2-20090312
 浙公网安备 33010602000005号
管理登录
浙公网安备 33010602000005号
管理登录


通过以下途径
即刻开启一站式全网营销体验
 上一篇
上一篇